深入研究基于Taint Analysis的自动化漏洞挖掘(Or 安全策略)
污点分析,一个算是很远古的手法,他的测试逻辑可谓毫无技术含量,但是他的出现也为AI自动化漏洞挖掘开了很大一块领地,直到今天,它依旧作为AI自动化漏洞挖掘的主要核心技术
回到技术本身,原则上它属于一个基于源码完整的Fuzzing框架,是一种追踪并分析污点信息在程序中流动的技术。在漏洞分析中,将所感兴趣的数据标记为污点数据(一般是程序的外部输入源),然后通过跟踪和污点数据相关的流向,观察他们是否会影响关键的程序操作,引发未知行为的漏洞,然后根据具体行为,对漏洞链进行还原,即完成了一个漏洞的挖掘,整个过程只需要针对该框架进行设计Fuzzing流程。
所以,它本质上就是一种调试手段,而非攻击手段,属一种安全校验技术,与BROP(外部Fuzzing)完全相反,它属于内部Fuzzing,某些情况下需要对目标进行一定的修改,或运行在特定的系统上。
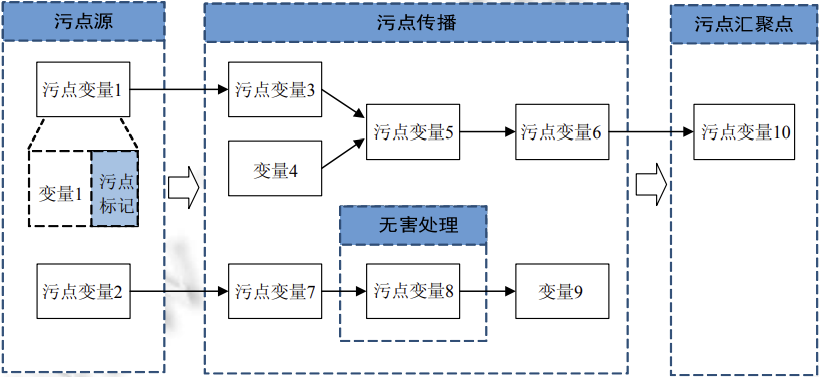
污点分析可以抽象成一个三元组:
- sources / 污点源(即直接引入不受信任的数据或者敏感数据到系统)
- sinks / 污点汇聚点(代表直接产生安全敏感操作(违反数据完整性)或者泄漏隐私数据到外界(违反数据保密性))
- sanitizers / 无害处理(代表通过数据加密或者移除危害操作等手段使数据传播不再对软件系统的信息安全产生危害)
污点分析就是观测由sources引入的数据是否能够不经sanitizers而直接传播到sinks处,如果不能,说明信息流是安全的;否则,说明产生了数据流危险,具体体现为隐私数据泄漏或危险数据操作等安全问题
技术的处理过程可以分成三个阶段
- 识别合适的污点源和汇聚点
通常使用启发式的策略进行标记,例如把程序所有的外部输入的数据全部标记污点,保守的认为这些数据有可能包含恶意的攻击数据; 或者使用工具,利用其根据具体应用调用的API或者重要的数据类型,手工标记sources和sinks 其次就是使用统计或AI自动识别和标记(也是目前的大方向,大体结构已经成熟)
- 污点传播观测分析
观测分析中的显式流分析就是分析污点如何随程序中变量之间的数据依赖关系继承 隐式流分析是分析污点如何随程序中变量之间的控制依赖关系传播,也就是污点如何从条件指令传播到其所控制的语句 然后去同步观察污点扩散距离核心数据或危险函数的"距离",发散分析,最后还原污点链
- 无害处理
污点数据在传播的过程中可能会经过无害化处理模块,具体是指sources经过该模块的处理后,数据本身不再携带铭感信息或者针对该数据的操作不会再对系统产生危害 所以,污点数据在经过这些无害化处理模块后,相应的sources标记可以被移除
所以从开发者角度来说,正确的使用无害处理可以降低系统中sources的数量 从分析角度来说,手动标记无害处理(例如无关函数,或无意义函数)可以让sources少走弯路,提高污点分析的效率,并且提高准确率
by the way. 加密库函数应该被识别成无害处理模块,一方面是由于库函数中使用了大量的加密算法,攻击者很难有效的还原计算密码的可能范围,另一方面是加密后的数据不再具有威胁性,继续传播sources没有意义(除非程序对其进行再解码并传播,所以可以在解密函数的范围重新对其打上sources,提高精确度)
具体数据流观测分析方法:
技术遵循链污染体系:
数据依赖传播(显式信息流)
污点传播分析中的显式流分析就是分析五点标记如何随程序中变量之间的(数据依赖关系)传播
即,我们标记变量x为污染点,在程序后续的逻辑中,如果变量x作为了别的表达式的操作数,那么操作结果也是污染的,以此类推,操作结果的后续逻辑会继续污染下去
相反,如果一个被污染的变量被赋值了一个常数,那么他就不再处于污染状态,所以转变成未污染
然后我们去相应的Sinks点进行观察,如果Sinks点的行为不能受程序输入的影响,那么就要检查Sinks点的条件值是否被污染
控制依赖传播(隐式信息流)
污点传播分析中的隐式流分析是分析污点标记如何随程序中变量之间的(控制依赖关系)传播,也就是分析污点标记如何从条件指令传播到其所控制的语句
如果一个控制表达式会受到某一个变量的影响行为,那么这个表达式受影响后的行为所操作的变量也属于污染变量
技术具体实现方法:
静态分析技术
指在不运行且不修改代码的前提下,通过分析程序变量间的数据依赖关系来检测数据能否从sources传播到sinks
静态分析的对象一般是程序的源码或中间表示,可以将对污点传播中显式流的静态分析问题转化为对程序中静态数据依赖的分析: 首先根据程序中的函数调用关系构建调用图(Call Graph,CG),然后,在函数内或函数间根据不同的程序特性进行具体的分析,常见的显式流sources传播方式包括直接赋值传播、通过函数(过程)调用传播以及通过**别名(指针)**传播。
以所示的程序为例(直接copy文献的): 第 3 行的变量 b 为初始的污点标记变量,程序第 4 行将一个包含变量 b 的算术表达式的计算结果直接赋给变量 c.由于变量 c 和变量 b 之间具有直接的赋值关系,污点标记可直接从赋值语句右部的变量传播到左部,也就是上述 3 种显式流污点传播方式中的直接赋值传播. 接下来,变量 c 被作为实参 传递给程序第 5 行的函数 foo,c 上的污点标记也通过函数调用传播到 foo 的形参 z,z 的污点标记又通过直接赋 值传播到程序第 8 行的 x.f. 由于 foo 的另外两个参数对象 x 和 y 都是对对象 a 的引用,二者之间存在别名,因此,x.f 的污点标记可以通过别名传播到第 9 行的污点汇聚点,程序存在泄漏问题.

动态分析技术
指在程序运行过程中,通过实时监控程序的污点数据在系统程序中的传播来检测数据是否能从sources传播到sinks 动态分析需要为污点数据扩展一个污点标记的标签(而不是直接修改变量内的数据指,因为这可能会引起程序的非预期运行逻辑)并将其存储在存储单元中,然后根据指令类型和指令操作数设计相应的传播逻辑传播污点标记
动态传播分析按照实现层次被分为基于硬件、基于软件以及混合型的污点传播分类这三类
基于硬件的污点传播分析需要定制的硬件支持,一般需要在原有体系结构上为寄存器或者内存扩展一个标记位(用于存放sources点的标签,如果没有这个寄存器,那么只能依赖于FS,但是效率大幅下降),用于存储污点标记(代表的系统有Minos,Raksha等)
基于软件的污点传播的有点在与不必更改处理器等底层的硬件,并且可以支持更高的语义逻辑的安全策略(利用其更贴近源程序层次的特点),但缺点是使用Instrumentation或对代码进行Rewriting,修改程序往往会给分析系统带来巨大的开销,相反的基于硬件的污点传播分析虽然可以利用定制硬件降低开销,但通常不能支持更高的语义逻辑的安全策略,并且需要对处理器结构进行重新设计
混合型的污点分析就是对前两者的方法折中,即通过经可能少的硬件结构改动以保证更高的语义逻辑的安全策略(代表的系统有Flexitaint,PIFT等)
技术展望以及个人理解:
待续… 后面想起来了再继续研究了
抛出一点问题
1,如何对Private的污点进行观测
2,如果污点回调链中含有不可访问段那么依赖工具生成的结果又是否可用?(在Agent中又是如何解决的)
3,是否依赖于HOOK,被观测的目标是否无感
5,“Needed for sound analysis.”
6.......